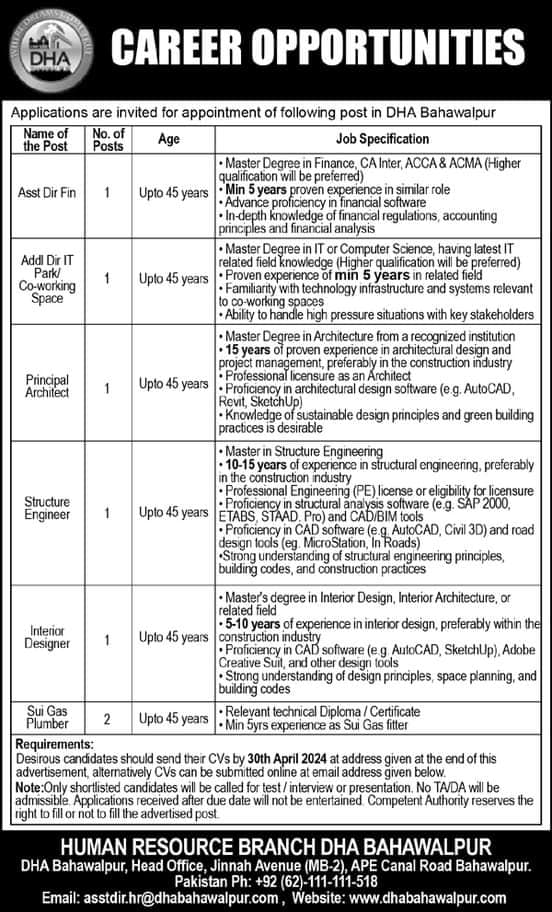
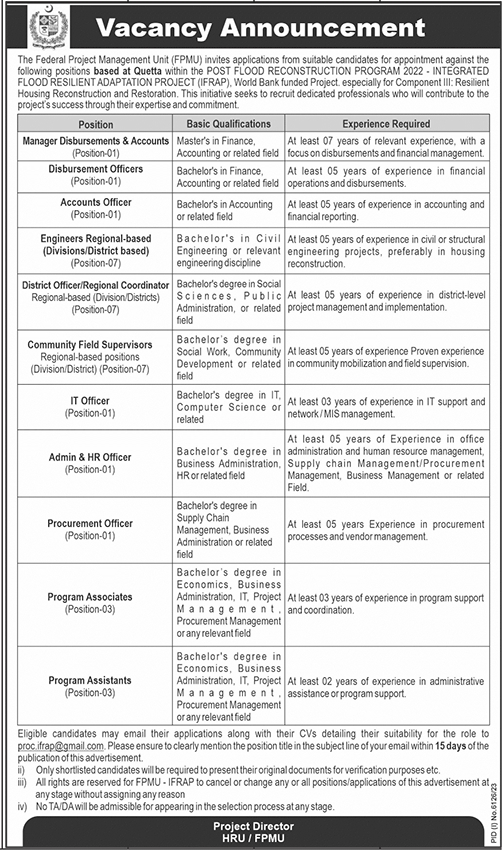
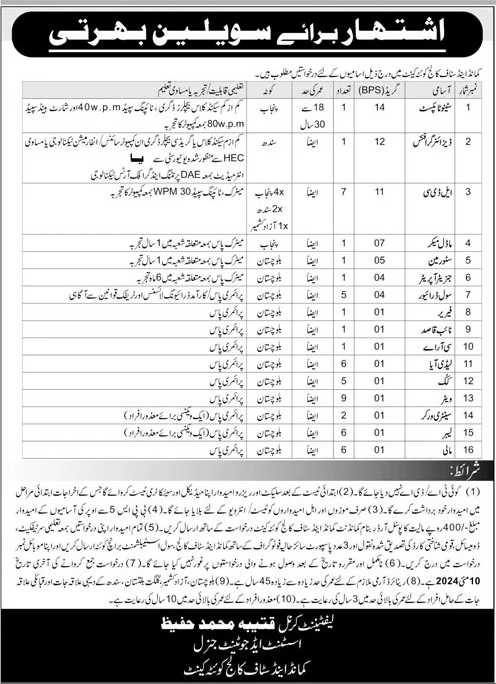
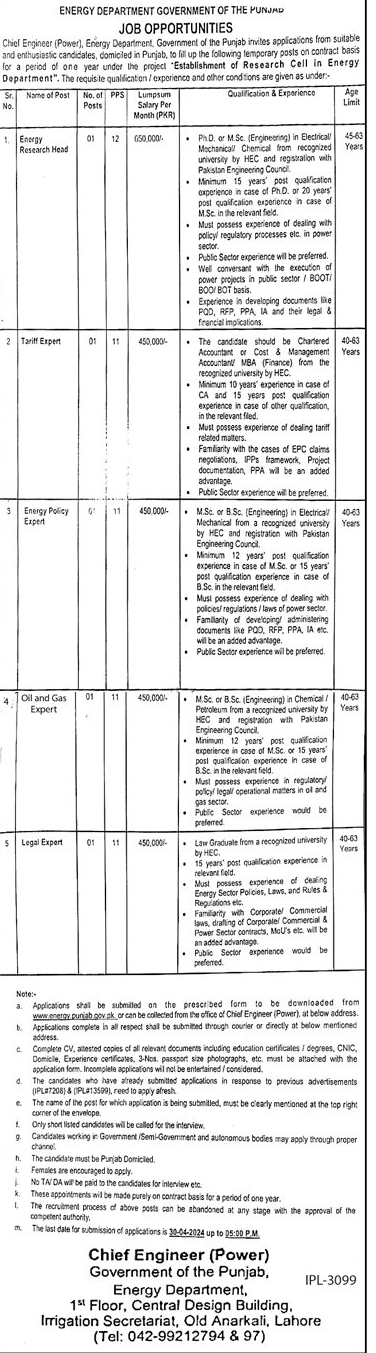
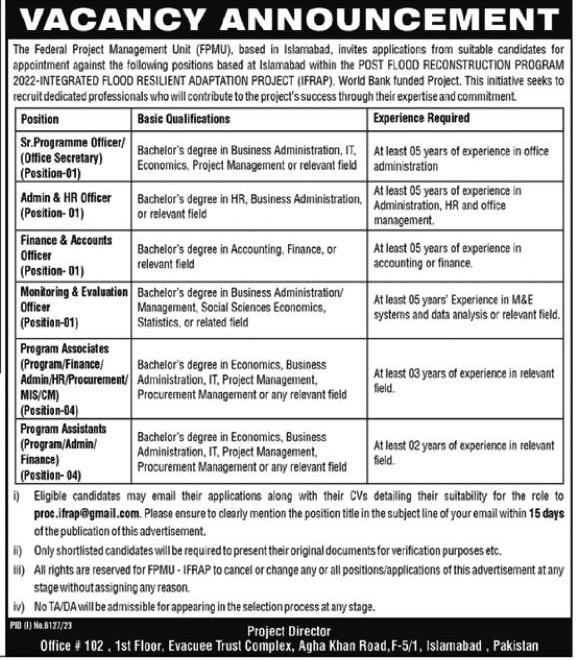
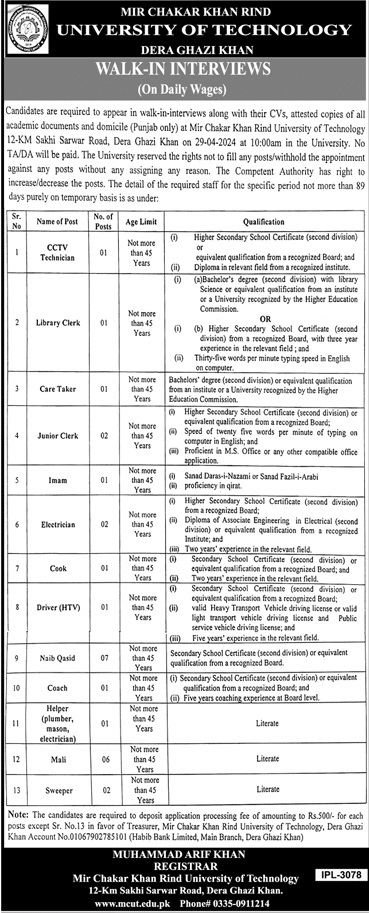
Municipal Committee Sui Latest Jobs 2024
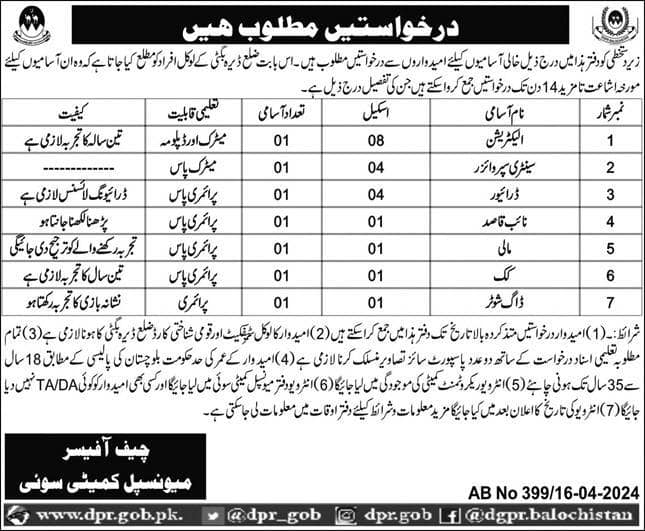
In 2024, an announcement has been made regarding the temporary promotions from BPS-01 to BPS-08. Local residents of District Dera Bugti are invited to apply for these positions. The advertisement was published on 17-04-2024. Interested candidates can submit their applications within the deadline mentioned in the advertisement. The details are as follows: BPS-01 to BPS-08 …